
- Dark Web Monitoring APIs aggregate data from infostealer logs, paste sites, and TOR marketplaces to detect exposed credentials in near real time.
- Infostealer logs are a primary source of leaked data, often containing emails, passwords, session cookies, and device-level metadata.
- Paste sites and TOR marketplaces act as fast-moving distribution channels where stolen credentials and sensitive data are rapidly shared or sold.
- These APIs normalize and enrich unstructured threat data to enable structured identity matching, risk scoring, and automated security responses.
- Real-time detection is critical because compromised credentials are frequently reused within minutes, making early exposure alerts essential for prevention.
A single leaked credential can move quietly from a compromised laptop to a global marketplace within hours, appearing first in an infostealer log, then resurfacing on a paste site, and eventually being sold in a TOR-based channel. By the time traditional security tools detect abnormal activity, the same data may already be reused across multiple fraud attempts.
This is the environment where Dark Web Monitoring APIs have become essential for developers building identity security, fraud prevention, and threat intelligence products. These APIs turn scattered underground data into structured, actionable signals that applications can consume in real time.
Understanding The Data Ecosystem Behind Dark Web Monitoring
Dark web monitoring is not a single source problem. It is a distributed data ecosystem where different leak channels serve different stages of the cybercrime lifecycle.
Infostealer malware is one of the most significant contributors today. It infects endpoints, extracts browser credentials, session tokens, and autofill data, then packages everything into structured logs. These logs are sold in bulk and reused across multiple criminal channels.
Paste sites function as rapid distribution points. Attackers dump credentials, API keys, or database samples publicly or semi-publicly. These are often short-lived but highly damaging due to immediate indexing and redistribution.
TOR marketplaces and forums represent the monetization layer. Stolen accounts, access credentials, and corporate data are packaged into listings where buyers can filter by geography, domain, or privilege level.
The result is a continuous flow of identity data moving across multiple surfaces, often within hours of compromise.
Why Traditional Security Tools Fail To Detect Exposure Early
Most security systems were built around perimeter defense and known threat signatures. That model does not work when the threat originates from legitimate credentials.
Once credentials are leaked, attackers do not need to bypass authentication systems. They reuse valid sessions or log in directly. This bypasses most detection layers unless exposure is known beforehand.
The global average cost of a data breach reached $4.88 million in 2024, with compromised credentials remaining one of the most common initial attack vectors.
74 percent of breaches involve the human element, including stolen credentials and misuse.
These numbers point to a consistent issue. Identity exposure happens before the attack, but detection often happens after.
What A Dark Web Monitoring API Is In Practice
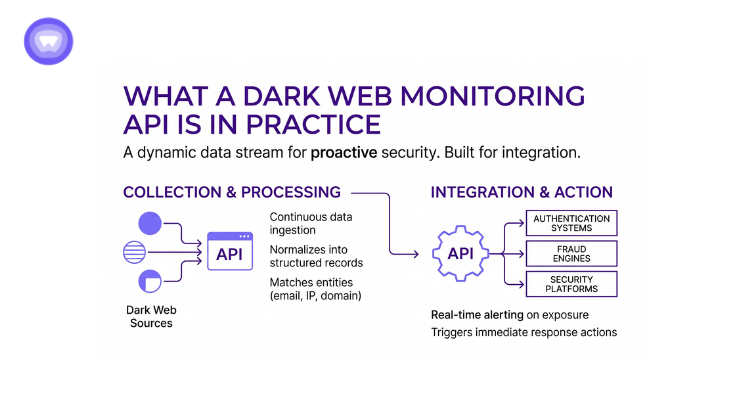
A Dark Web Monitoring API is a system that continuously collects threat data from underground sources and exposes it through structured endpoints for developers.
Unlike manual threat intelligence feeds, these APIs are built for integration. They are designed to be embedded inside authentication systems, fraud engines, or security operations platforms.
A typical API provides:
- Continuous ingestion of leaked datasets from multiple dark web sources
- Normalization of unstructured data into structured identity records
- Entity matching across email, domain, IP, and credential datasets
- Real-time alerting when monitored assets appear in new leaks
The goal is not just detection. It is operational readiness. Developers integrate these APIs into workflows where exposure triggers immediate response actions.
Core Data Sources Inside Monitoring Pipelines
A production-grade monitoring system does not rely on a single ingestion method. It aggregates multiple layers of underground data.
Infostealer Logs
These are among the most structured datasets in the dark web ecosystem. Each log often contains:
- Email and password pairs
- Browser cookies and session tokens
- Saved autofill identity data
- Installed applications and system metadata
Because they are machine-generated, they can be parsed with relatively high accuracy compared to other sources.
Paste Sites
Paste sites are unpredictable and fast-moving. Data is unstructured and varies widely in format. Developers typically rely on NLP parsing and pattern detection to extract meaningful fields such as:
- Email addresses
- API keys
- Database dumps
- Authentication tokens
The volatility of these sources makes them high priority for real-time scanning systems.
TOR Marketplaces
TOR-based platforms are where stolen data is monetized. Listings often include:
- Access credentials for corporate systems
- Full identity profiles
- Compromised accounts with verified login access
- Subscription-based data leaks
Unlike logs or pastes, marketplace data is conversational and requires contextual parsing.
System Architecture Of A Monitoring API
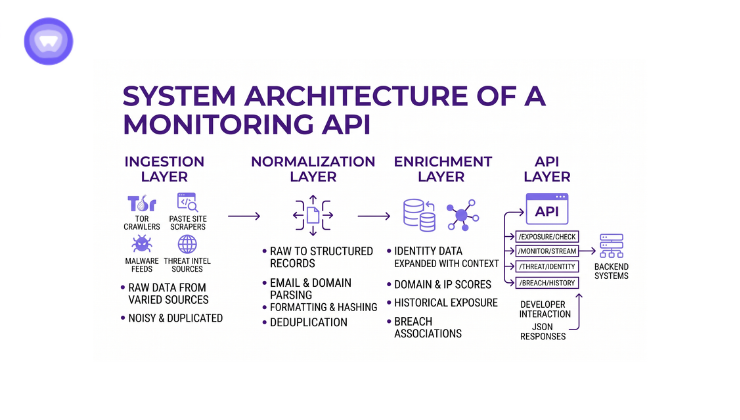
A scalable Dark Web Monitoring API is built as a multi-stage pipeline rather than a single service.
1. Ingestion Layer
This layer collects raw data from:
- TOR crawlers
- Paste site scrapers
- Malware feed integrations
- Third-party threat intelligence sources
Data is often noisy, duplicated, or partially encrypted.
2. Normalization Layer
Raw inputs are transformed into structured records. This stage includes:
- Email extraction and validation
- Domain parsing and normalization
- Credential formatting and hashing
- Deduplication across sources
The objective is to convert inconsistent data into a unified schema.
3. Enrichment Layer
At this stage, raw identity data is expanded with context:
- Domain reputation scoring
- Historical exposure tracking
- Breach association mapping
- IP geolocation correlation
- Related account linking
Enrichment is what turns raw leaks into actionable intelligence.
4. API Layer
This is what developers interact with directly. Common endpoints include:
- /exposure/check for identity lookup
- /monitor/stream for real-time feeds
- /threat/identity for user-level risk profiling
- /breach/history for historical exposure analysis
Responses are typically JSON-based and optimized for integration into backend systems.
Example Integration Flow In A Real System
A common implementation inside a security platform looks like this:
- A user logs into a SaaS application
- Authentication system validates credentials normally
- Dark Web Monitoring API continuously checks email and domain exposure
- API returns a match indicating credentials found in infostealer logs
- Risk engine increases user risk score
- System triggers step-up authentication or session reset
This flow does not interrupt authentication unless exposure is detected. It operates in parallel to login systems.
Detection Techniques Used In Modern Systems
Dark Web Monitoring APIs rely on multiple detection strategies to maintain accuracy.
Pattern-Based Extraction
Regular expressions identify structured data such as emails, IP addresses, and API keys.
Credential Matching
Hashed passwords and reused credentials are matched against known breach datasets and infostealer archives.
Behavioral Correlation
Systems correlate identity elements across multiple datasets, linking:
- Email reuse across platforms
- Domain ownership patterns
- Device fingerprints found in logs
Clustering and Classification
Machine learning models group unstructured paste data into probable breach events, reducing duplication and noise.
Operational Challenges In Dark Web Monitoring
Despite automation, several challenges remain:
Data Instability
Sources disappear frequently. TOR domains and paste sites rotate or shut down without notice.
High Noise Ratio
Not all leaked data is valid or usable. False positives are common, especially in reused credential datasets.
Parsing Complexity
Each source format differs significantly, requiring continuous parser updates.
Latency Constraints
Attackers often weaponize leaked credentials within minutes. Monitoring systems must operate in near real time.
Where Developers Use Dark Web Monitoring APIs
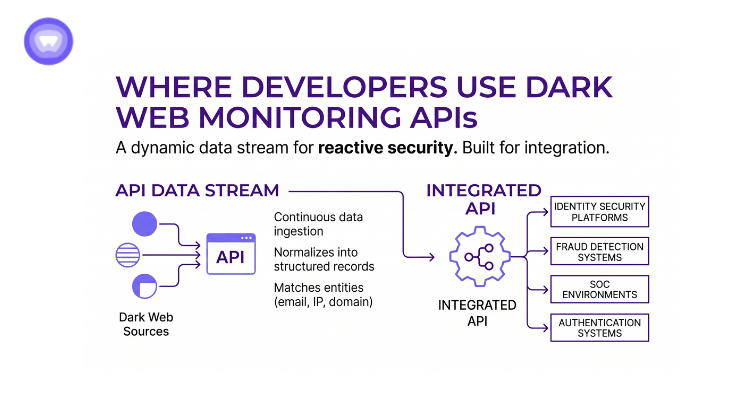
These APIs are embedded into multiple security workflows:
Identity Security Platforms
They detect compromised accounts and trigger password resets or MFA enforcement.
Fraud Detection Systems
They identify stolen identities used in account creation or transaction abuse.
SOC Environments
They feed exposure data into SIEM dashboards for continuous monitoring.
Authentication Systems
They adjust login security dynamically based on exposure risk.
Threat Context And Scale
The scale of identity exposure continues to grow across multiple vectors.
The average cost of a data breach reached $4.88 million in 2024, according to IBM.
Credential-based attacks remain one of the most common breach types, with human involvement present in most incidents.
Chainalysis also reported $24.2 billion in illicit crypto activity in 2023, reflecting the scale of monetized cybercrime infrastructure.
These figures reinforce a single reality. Identity exposure is not isolated. It is continuous and system-driven.
Where White-Label Infrastructure Fits In
Building monitoring systems is not only about detection logic. It also requires secure infrastructure for ingestion, processing, and internal access control.
PureWL’s white label VPN solution provides a deployable secure access layer that can support developers building distributed threat intelligence systems. It enables encrypted communication between ingestion pipelines, dashboards, and backend services without exposing internal infrastructure.
Within a Dark Web Monitoring API architecture, this kind of infrastructure helps secure data flows, isolate analysis environments, and protect internal threat processing systems from external exposure.
Final Thoughts
A Dark Web Monitoring API is ultimately a data engineering system built for security outcomes. It processes unstable, fast-moving, and unstructured threat data and converts it into structured signals that applications can act on immediately.
The effectiveness of these systems depends on coverage, processing speed, and how quickly exposed identity data is transformed into automated defensive action.